About Privacy¶
This chapter contains some general remarks on how you should design your study,
gather your data, and use odk_planner to avoid loosing control over your
study data. This is especially important if you work with patient data that
merits to be handled with very much consideration. But it equally applies to
less sensitive data whenever people are involved in your studies and entrust
you their data.
Note that this is a complicated topic that involves many fields and its surface is barely scratched in this very short chapter. Also, your organization has probably their own data management manual that describes in more detail what data you are allowed to collect and store how you have to handle these. Additionally, local laws apply, most probably in the country where you collect the data, and also in the country where you store the data.
Digitization¶
Beware the following : It is extremely easy to copy data once it is digitized. This means that you are probably better off not digitizing sensitive data in the first place, instead of trying to prevent everyone who will handle it to make it impossible to copy the data.
Of course, this puts you in a dilemma, since the whole idea of using ODK is to digitize your data for ease of collection and analysis. One possible way out is to digitze all data apart from identifying datapoints, such as name and addresses, which are rarely used for data analysis, and can be kept seperately in a paper register (or on an encrypted hard drive in the principal investor’s office).
Unfortunately, there are other datapoints that will turn up in your final data analysis but can easily be used to identify subjects. Think of coordinates for example. In these cases some more creativity is needed: you could for example add a random offset to locations so you can still use them to analyze distribution but at the same time the spatial resolution would not be sufficient to identify housings (and map them to an address book).
Database segregation¶
If you decide to include sensitive personal data in your database, then you should work out a database design with multiple databases. You can then store the sensitive data in a separate database. This has the advantage that you can define a different backup policy for the. Separating sensitive data in its own database also allows you to create separate database users (and passwords) that can only see part of the data.
Mind that, although you can also define access restrictions for viewing
data in okd_planner, it is not possible to restrict the
access of an user that has admin rights. And it is
always better to use additional safety guards to protect data.
Admin rights¶
It is important to realize that odk_planner has (read-only) access to the
entire database that stores the data for your study. If you use the same ODK
Aggregate instance for more than one study, then you can set up multiple
instances of odk_planner but users with admin
rights are free to define how they want to configure odk_planner (and can,
for example, create an overview that contains forms from other studies included
in the same database).
Therefore, you should restrict admin rights to as few users as possible,
ideally only to one person.
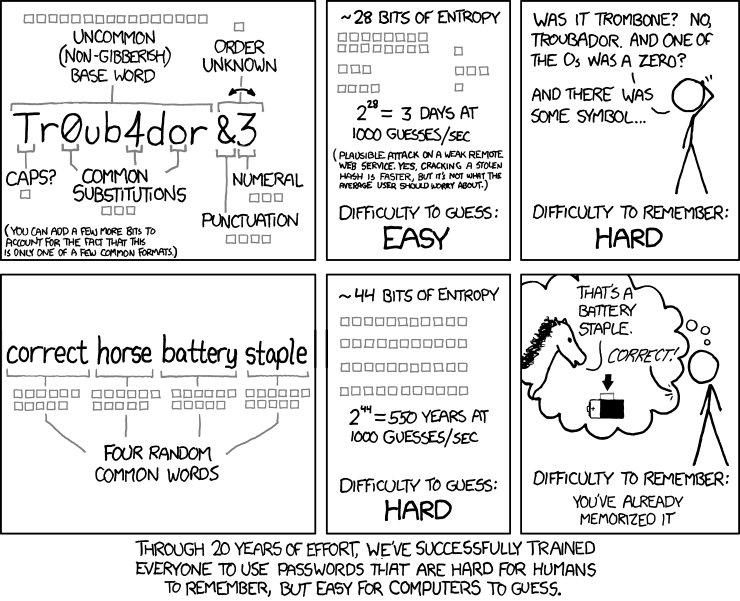
Choosing a good password¶
The access protection relies on good passwords. Without good passwords, it will be easy for strangers (or your users’ acquaintances) to guess a valid login and access all the study data!
Since the passwords are stored in plain text (i.e. users with admin rights
who can download the config.xls can see them), and because passwords that
are used for many different services are a lot easier to intercept somewhere,
you really should use an unique password that is solely used to identify
users with odk_planner.
The default password 0dk pa2sw0rd used throughout this documentation is
actually a really poor password. A word of wisdom from xkcd
{kind=link}